2D 卷积优化
单击 此处 下载完整的示例代码
本教程概述了如何用 TVM 在 VTA 设计上有效地映射 2D 卷积工作负载。推荐先学习 矩阵乘法分块 教程。
2D 卷积在大多数计算机视觉深度神经网络中占主导地位。本教程将演示 TVM schedule 优化,将 NCHW 布局中的 2D 卷积算子映射到 VTA。还引入了延迟隐藏的概念,使得最大限度地利用 VTA 的计算和内存资源。
RPC 设置
首先对 Pynq 的 FPGA 进行编程,并构建其 RPC runtime。
from __future__ import absolute_import, print_function
import os
import tvm
import tvm.testing
from tvm import te
import vta
import numpy as np
from tvm import rpc
from tvm.contrib import utils
from vta.testing import simulator
# 从 3rdparty/vta-hw/config/vta_config.json 文件加载 VTA 参数
env = vta.get_env()
# 从 OS 环境中读取 Pynq RPC 主机 IP 地址和端口号
host = os.environ.get("VTA_RPC_HOST", "192.168.2.99")
port = int(os.environ.get("VTA_RPC_PORT", "9091"))
# 在 Pynq 上配置比特流和 runtime 系统,匹配 vta_config.json 文件指定的 VTA 配置。
if env.TARGET == "pynq":
# 确保 TVM 是用 RPC=1 编译的
assert tvm.runtime.enabled("rpc")
remote = rpc.connect(host, port)
# 重新配置 JIT runtime
vta.reconfig_runtime(remote)
# 用预编译的 VTA 比特流对 FPGA 进行编程。
# 可以通过传递比特流文件的路径而非 None,用自定义比特流对 FPGA 进行编程。
vta.program_fpga(remote, bitstream=None)
# 在模拟模式下,本地托管 RPC 服务器。
elif env.TARGET in ["sim", "tsim"]:
remote = rpc.LocalSession()
计算声明
第一步,用 NCHW 格式描述 2D 卷积计算。
通过 batch size、空间维度、输入通道、输出通道、内核维度、填充维度和步长维度来定义 2D 卷积 shape。
将 ResNet-18 架构的第 9 个卷积层的 shape 作为卷积工作负载参数。
在 2D 卷积中添加了额外的算子,这些算子对输出进行移位和裁剪,从而模拟定点卷积,然后进行校正线性激活。下面描述 2D 卷积层的 TVM 数据流图:
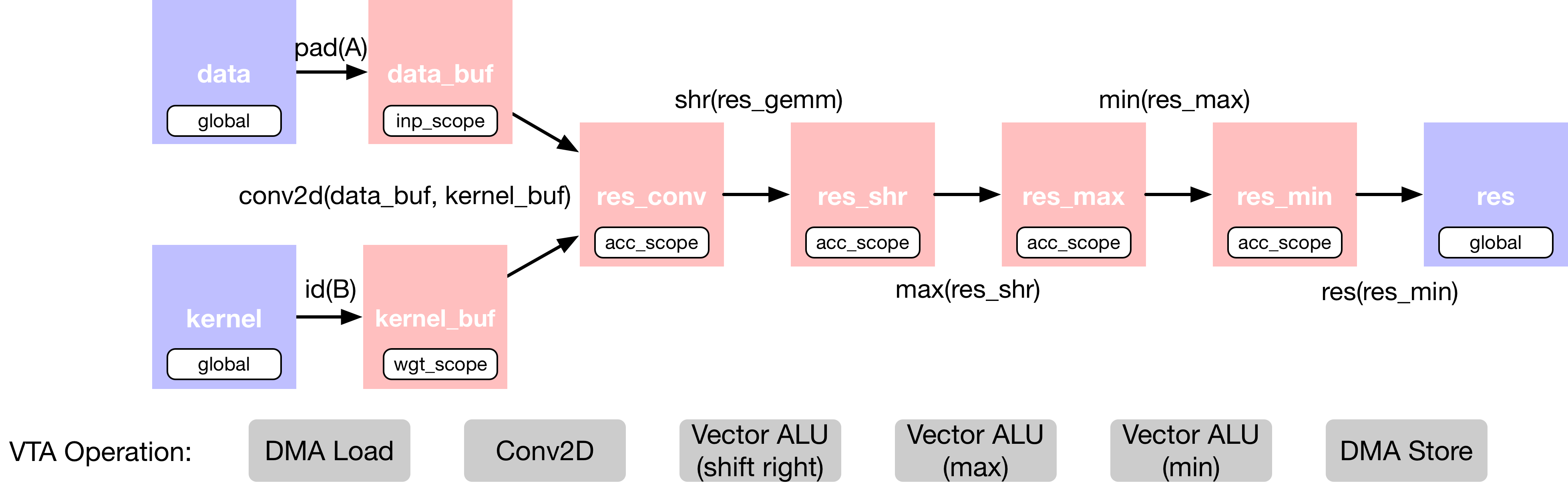
由于这种计算太大,无法一次全部放入 VTA 的芯片缓冲区。因此,在调度阶段,我们将依靠计算分块策略,将计算分解为易于管理的块。
空间填充
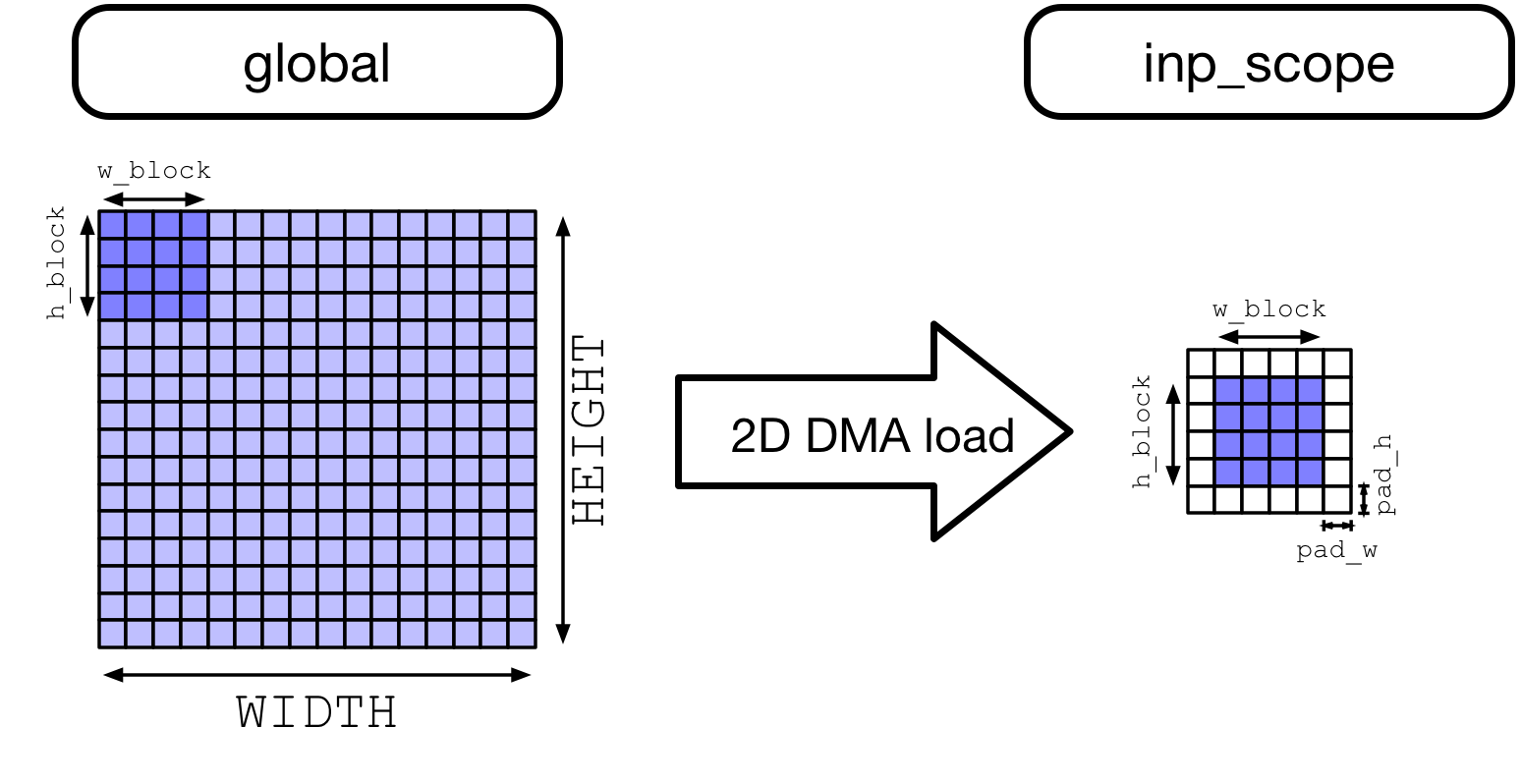
注意,要导入 TOPI 库,在输入特征图张量上应用空间填充。空间填充有助于在 2D 卷积的上下文中进行分块,因为若卷积核窗口大小大于 1,则对于任何给定层的输入特征图,相同的 (x, y) 空间位置会被多次读取。
在 CPU 和 GPU 上,并行化工作时提高内存访问效率的一种方法是空间打包,这种方法要对数据进行重新布局。VTA 加载 DMA 引擎可以自动插入填充,因此不必将原始输入特征图重新打包到内存中。
我们展示了数据从 DRAM 加载到 VTA 的 SRAM 中时,VTA 的动态空间填充效果。这个过程发生在 2D 跨步和填充内存(strided and padded memory)读取后。
from tvm import topi
# 2D 卷积层尺寸取自 ResNet-18 架构(第 9 个卷积层)
batch_size = 1
height = 14
width = 14
in_channels = 256
out_channels = 256
kernel_h = 3
kernel_w = 3
pad_h = 1
pad_w = 1
stride_h = 1
stride_w = 1
assert batch_size % env.BATCH == 0
assert in_channels % env.BLOCK_IN == 0
assert out_channels % env.BLOCK_OUT == 0
# 输入特征图:(N, IC, H, W, n, ic)
data_shape = (
batch_size // env.BATCH,
in_channels // env.BLOCK_IN,
height,
width,
env.BATCH,
env.BLOCK_IN,
)
# 内核:(OC,IC,H,W,oc,ic)
kernel_shape = (
out_channels // env.BLOCK_OUT,
in_channels // env.BLOCK_IN,
kernel_h,
kernel_w,
env.BLOCK_OUT,
env.BLOCK_IN,
)
# 导出输出特征图维度
fout_height = (height + 2 * pad_h - kernel_h) // stride_h + 1
fout_width = (width + 2 * pad_w - kernel_w) // stride_w + 1
# 输出特征图:(N, OC, H, W, n, oc)
output_shape = (
batch_size // env.BATCH,
out_channels // env.BLOCK_OUT,
fout_height,
fout_width,
env.BATCH,
env.BLOCK_OUT,
)
# 卷积 reduction 轴
dy = te.reduce_axis((0, kernel_h), name="dy")
dx = te.reduce_axis((0, kernel_w), name="dx")
ic = te.reduce_axis((0, in_channels // env.BLOCK_IN), name="ic")
ic_tns = te.reduce_axis((0, env.BLOCK_IN), name="ic_tns")
# 输入占位符张量
data = te.placeholder(data_shape, name="data", dtype=env.inp_dtype)
kernel = te.placeholder(kernel_shape, name="kernel", dtype=env.wgt_dtype)
# 复制缓冲区:
# 对输入特征图应用空间填充
data_buf = topi.nn.pad(data, [0, 0, pad_h, pad_w, 0, 0], name="data_buf")
kernel_buf = te.compute(kernel_shape, lambda *i: kernel(*i), "kernel_buf")
# 声明二维卷积
res_conv = te.compute(
output_shape,
lambda bo, co, i, j, bi, ci: te.sum(
data_buf[bo, ic, i * stride_h + dy, j * stride_w + dx, bi, ic_tns].astype(env.acc_dtype)
* kernel_buf[co, ic, dy, dx, ci, ic_tns].astype(env.acc_dtype),
axis=[ic, dy, dx, ic_tns],
),
name="res_conv",
)
# 为定点归一化添加移位阶段
res_shr = te.compute(output_shape, lambda *i: res_conv(*i) >> 8, name="res_shr")
# 在(0,输入最大值)之间应用 clip 函数
inp_max = (1 << (env.INP_WIDTH - 1)) - 1
res_max = te.compute(output_shape, lambda *i: tvm.te.max(res_shr(*i), 0), "res_max")
res_min = te.compute(output_shape, lambda *i: tvm.te.min(res_max(*i), inp_max), "res_min")
# 结果张量
res = te.compute(output_shape, lambda *i: res_min(*i).astype(env.inp_dtype), name="res")
调度计算
下面将研究用有效方式将 2D 卷积映射到 VTA 所需的一组调度转换。包括:
- 计算分块
- 增加计算利用率的虚拟线程
- 降级到 VTA 硬件内联函数
# 创建 TVM schedule
s = te.create_schedule(res.op)
# 查看默认的 TVM schedule
print(tvm.lower(s, [data, kernel, res], simple_mode=True))
输出结��果:
@main = primfn(data_1: handle, kernel_1: handle, res_1: handle) -> ()
attr = {"from_legacy_te_schedule": True, "global_symbol": "main", "tir.noalias": True}
buffers = {data: Buffer(data_2: Pointer(int8), int8, [50176], []),
kernel: Buffer(kernel_2: Pointer(int8), int8, [589824], []),
res: Buffer(res_2: Pointer(int8), int8, [50176], [])}
buffer_map = {data_1: data, kernel_1: kernel, res_1: res}
preflattened_buffer_map = {data_1: data_3: Buffer(data_2, int8, [1, 16, 14, 14, 1, 16], []), kernel_1: kernel_3: Buffer(kernel_2, int8, [16, 16, 3, 3, 16, 16], []), res_1: res_3: Buffer(res_2, int8, [1, 16, 14, 14, 1, 16], [])} {
allocate(data_buf: Pointer(global int8), int8, [65536]), storage_scope = global;
allocate(kernel_buf: Pointer(global int8), int8, [589824]), storage_scope = global;
allocate(res_conv: Pointer(global int32), int32, [50176]), storage_scope = global {
for (i1: int32, 0, 16) {
for (i2: int32, 0, 16) {
for (i3: int32, 0, 16) {
for (i5: int32, 0, 16) {
let cse_var_1: int32 = (i3*16)
data_buf_1: Buffer(data_buf, int8, [65536], [])[((((i1*4096) + (i2*256)) + cse_var_1) + i5)] = @tir.if_then_else(((((1 <= i2) && (i2 < 15)) && (1 <= i3)) && (i3 < 15)), data[(((((i1*3136) + (i2*224)) + cse_var_1) + i5) - 240)], 0i8, dtype=int8)
}
}
}
}
for (i0: int32, 0, 16) {
for (i1_1: int32, 0, 16) {
for (i2_1: int32, 0, 3) {
for (i3_1: int32, 0, 3) {
for (i4: int32, 0, 16) {
for (i5_1: int32, 0, 16) {
let cse_var_2: int32 = ((((((i0*36864) + (i1_1*2304)) + (i2_1*768)) + (i3_1*256)) + (i4*16)) + i5_1)
kernel_buf_1: Buffer(kernel_buf, int8, [589824], [])[cse_var_2] = kernel[cse_var_2]
}
}
}
}
}
}
for (co: int32, 0, 16) {
for (i: int32, 0, 14) {
for (j: int32, 0, 14) {
for (ci: int32, 0, 16) {
res_conv_1: Buffer(res_conv, int32, [50176], [])[((((co*3136) + (i*224)) + (j*16)) + ci)] = 0
for (ic: int32, 0, 16) {
for (dy: int32, 0, 3) {
for (dx: int32, 0, 3) {
for (ic_tns: int32, 0, 16) {
let cse_var_4: int32 = (j*16)
let cse_var_3: int32 = ((((co*3136) + (i*224)) + cse_var_4) + ci)
res_conv_1[cse_var_3] = (res_conv_1[cse_var_3] + (cast(int32, data_buf_1[((((((ic*4096) + (i*256)) + (dy*256)) + cse_var_4) + (dx*16)) + ic_tns)])*cast(int32, kernel_buf_1[((((((co*36864) + (ic*2304)) + (dy*768)) + (dx*256)) + (ci*16)) + ic_tns)])))
}
}
}
}
}
}
}
}
for (i1_2: int32, 0, 16) {
for (i2_2: int32, 0, 14) {
for (i3_2: int32, 0, 14) {
for (i5_2: int32, 0, 16) {
let cse_var_5: int32 = ((((i1_2*3136) + (i2_2*224)) + (i3_2*16)) + i5_2)
res_conv_2: Buffer(res_conv, int32, [50176], [])[cse_var_5] = @tir.shift_right(res_conv_1[cse_var_5], 8, dtype=int32)
}
}
}
}
for (i1_3: int32, 0, 16) {
for (i2_3: int32, 0, 14) {
for (i3_3: int32, 0, 14) {
for (i5_3: int32, 0, 16) {
let cse_var_6: int32 = ((((i1_3*3136) + (i2_3*224)) + (i3_3*16)) + i5_3)
res_conv_3: Buffer(res_conv, int32, [50176], [])[cse_var_6] = max(res_conv_2[cse_var_6], 0)
}
}
}
}
for (i1_4: int32, 0, 16) {
for (i2_4: int32, 0, 14) {
for (i3_4: int32, 0, 14) {
for (i5_4: int32, 0, 16) {
let cse_var_7: int32 = ((((i1_4*3136) + (i2_4*224)) + (i3_4*16)) + i5_4)
res_conv_4: Buffer(res_conv, int32, [50176], [])[cse_var_7] = min(res_conv_3[cse_var_7], 127)
}
}
}
}
for (i1_5: int32, 0, 16) {
for (i2_5: int32, 0, 14) {
for (i3_5: int32, 0, 14) {
for (i5_5: int32, 0, 16) {
let cse_var_8: int32 = ((((i1_5*3136) + (i2_5*224)) + (i3_5*16)) + i5_5)
res[cse_var_8] = cast(int8, res_conv_4[cse_var_8])
}
}
}
}
}
}
对计算分块
默认情况下,2D 卷积对于激活或内核权重来说太大,无法一次性同时装入 VTA 的芯片缓冲区。沿输入通道、输出通道和高度空间维度分块。不要沿宽度空间维度分块,因为它是 NCHW 布局中的最内层维度��(因此,为了增加局部性,最好不要沿最内层维度进行阻塞)。
# 定义平铺大小
b_block = 1 // env.BATCH
oc_block = 128 // env.BLOCK_OUT
ic_block = 16 // env.BLOCK_IN
h_block = 7
w_block = 14
# 沿空间和输出通道维度平铺输出张量
# (因为默认进行单个 batch 推理,沿 batch 维度的拆分没有效果)
b, oc, y, x, b_tns, oc_tns = s[res].op.axis
b_out, b_inn = s[res].split(b, factor=b_block)
oc_out, oc_inn = s[res].split(oc, factor=oc_block)
y_out, y_inn = s[res].split(y, factor=h_block)
x_out, x_inn = s[res].split(x, factor=w_block)
s[res].reorder(b_out, oc_out, y_out, x_out, b_inn, oc_inn, y_inn, x_inn, b_tns, oc_tns)
# 将中间计算移动到每个输出计算块中
s[res_conv].compute_at(s[res], x_out)
s[res_shr].compute_at(s[res], x_out)
s[res_max].compute_at(s[res], x_out)
s[res_min].compute_at(s[res], x_out)
# 沿 reduction 轴(输入通道)应用额外的循环分割
b_inn, oc_inn, y_inn, x_inn, b_tns, oc_tns = s[res_conv].op.axis
ic_out, ic_inn = s[res_conv].split(ic, factor=ic_block)
# 对轴重新排序。
# 1)在最里面的位置将 VTA 张量轴分组:b_tns、oc_tns、ic_tns,使得 TVM 张量化。
# 2)将 ic_out 轴移出卷积循环,沿 reduction 轴阻塞。
# 3)现在对块轴重新排序:b_inn、oc_inn、y_inn、x_inn、ic_inn、dy、dx。
# VTA runtime/硬件要求为每个 VTA 张量操作写入不同的输出特征图位置。
# 这个限制要求在 b_tns 之前对 oc_inn、y_inn 或 x_inn 其中之一进行排序,因为它们都会影响输出特征图索引。
# 下面将 x_inn 放进去。
s[res_conv].reorder(ic_out, b_inn, oc_inn, y_inn, ic_inn, dy, dx, x_inn, b_tns, oc_tns, ic_tns)
虚拟线程
虚拟线程是 VTA 硬件设计中,一种提高任务级 pipeline 并行性的机制。换言之,它通过隐藏内存访问延迟,来提高计算资源利用率。
以下实现,虚拟线程将工作分配给沿输出通道轴拆分的两个线程。下图展示了计算 2D 卷积时,工作是如何划分的。
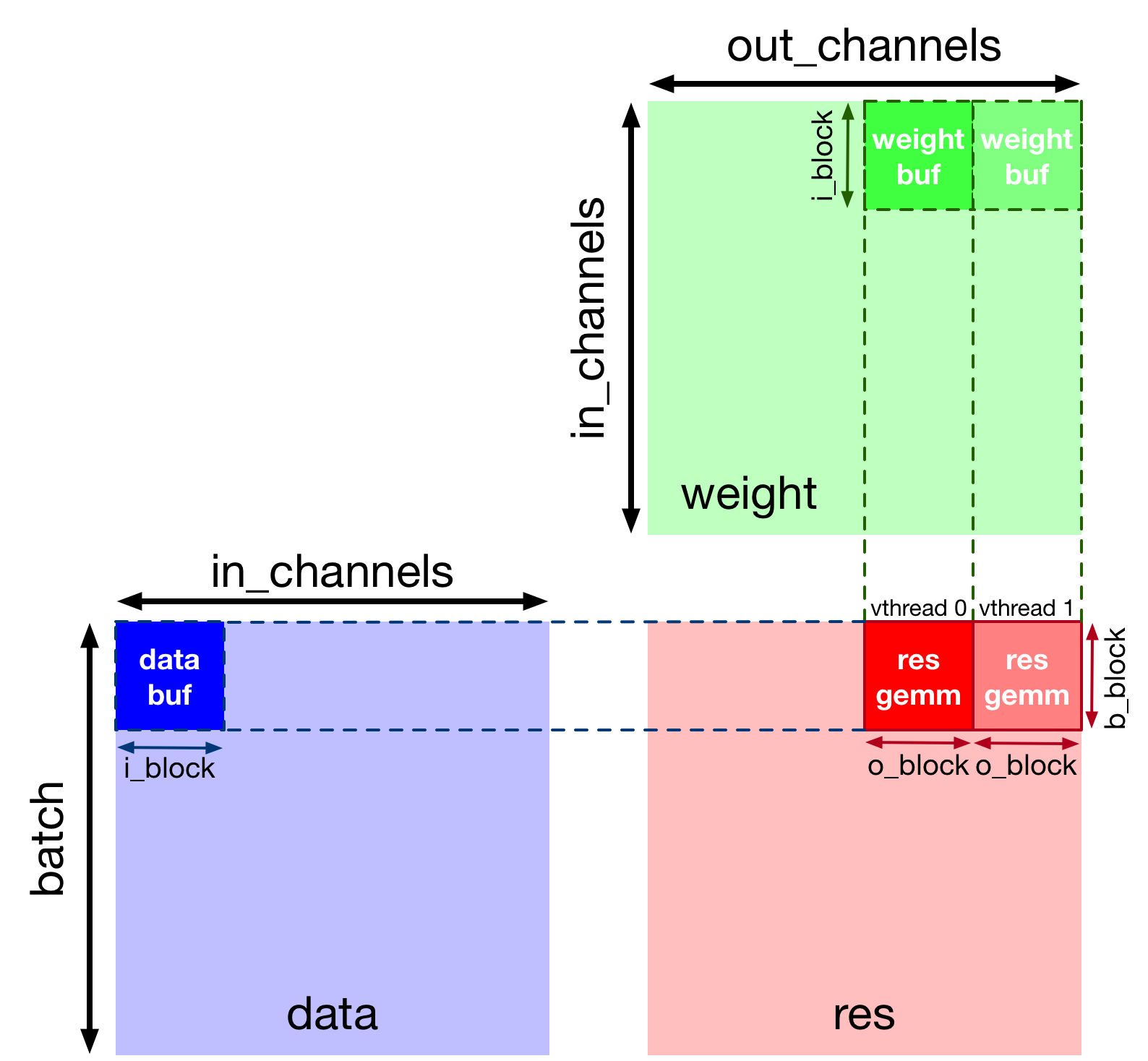
# VTA 只支持 2 个虚拟线程
v_threads = 2
# 沿输出通道外轴进行虚拟线程拆分
_, tx = s[res].split(oc_out, factor=v_threads)
s[res].reorder(tx, b_out)
s[res].bind(tx, te.thread_axis("cthread"))
# 查看��阻塞和虚拟线程后的当前 TVM schedule
print(tvm.lower(s, [data, kernel, res], simple_mode=True))
输出结果:
@main = primfn(data_1: handle, kernel_1: handle, res_1: handle) -> ()
attr = {"from_legacy_te_schedule": True, "global_symbol": "main", "tir.noalias": True}
buffers = {data: Buffer(data_2: Pointer(int8), int8, [50176], []),
kernel: Buffer(kernel_2: Pointer(int8), int8, [589824], []),
res: Buffer(res_2: Pointer(int8), int8, [50176], [])}
buffer_map = {data_1: data, kernel_1: kernel, res_1: res}
preflattened_buffer_map = {data_1: data_3: Buffer(data_2, int8, [1, 16, 14, 14, 1, 16], []), kernel_1: kernel_3: Buffer(kernel_2, int8, [16, 16, 3, 3, 16, 16], []), res_1: res_3: Buffer(res_2, int8, [1, 16, 14, 14, 1, 16], [])} {
allocate(data_buf: Pointer(global int8), int8, [65536]), storage_scope = global;
allocate(kernel_buf: Pointer(global int8), int8, [589824]), storage_scope = global;
allocate(res_conv: Pointer(global int32), int32, [25088]), storage_scope = global {
for (i1: int32, 0, 16) {
for (i2: int32, 0, 16) {
for (i3: int32, 0, 16) {
for (i5: int32, 0, 16) {
let cse_var_1: int32 = (i3*16)
data_buf_1: Buffer(data_buf, int8, [65536], [])[((((i1*4096) + (i2*256)) + cse_var_1) + i5)] = @tir.if_then_else(((((1 <= i2) && (i2 < 15)) && (1 <= i3)) && (i3 < 15)), data[(((((i1*3136) + (i2*224)) + cse_var_1) + i5) - 240)], 0i8, dtype=int8)
}
}
}
}
for (i0: int32, 0, 16) {
for (i1_1: int32, 0, 16) {
for (i2_1: int32, 0, 3) {
for (i3_1: int32, 0, 3) {
for (i4: int32, 0, 16) {
for (i5_1: int32, 0, 16) {
let cse_var_2: int32 = ((((((i0*36864) + (i1_1*2304)) + (i2_1*768)) + (i3_1*256)) + (i4*16)) + i5_1)
kernel_buf_1: Buffer(kernel_buf, int8, [589824], [])[cse_var_2] = kernel[cse_var_2]
}
}
}
}
}
}
for (i2.outer: int32, 0, 2) {
for (co.init: int32, 0, 8) {
for (i.init: int32, 0, 7) {
for (j.init: int32, 0, 14) {
for (ci.init: int32, 0, 16) {
let cse_var_3: int32 = ((((co.init*1568) + (i.init*224)) + (j.init*16)) + ci.init)
{
res_conv_1: Buffer(res_conv, int32, [157351936], [])[cse_var_3] = 0
res_conv_1[(cse_var_3 + 12544)] = 0
}
}
}
}
}
for (ic.outer: int32, 0, 16) {
for (co: int32, 0, 8) {
for (i: int32, 0, 7) {
for (dy: int32, 0, 3) {
for (dx: int32, 0, 3) {
for (j: int32, 0, 14) {
for (ci: int32, 0, 16) {
for (ic_tns: int32, 0, 16) {
let cse_var_8: int32 = (j*16)
let cse_var_7: int32 = ((((co*1568) + (i*224)) + cse_var_8) + ci)
let cse_var_6: int32 = (cse_var_7 + 12544)
let cse_var_5: int32 = ((((((co*36864) + (ic.outer*2304)) + (dy*768)) + (dx*256)) + (ci*16)) + ic_tns)
let cse_var_4: int32 = (((((((ic.outer*4096) + (i2.outer*1792)) + (i*256)) + (dy*256)) + cse_var_8) + (dx*16)) + ic_tns)
{
res_conv_1[cse_var_7] = (res_conv_1[cse_var_7] + (cast(int32, data_buf_1[cse_var_4])*cast(int32, kernel_buf_1[cse_var_5])))
res_conv_1[cse_var_6] = (res_conv_1[cse_var_6] + (cast(int32, data_buf_1[cse_var_4])*cast(int32, kernel_buf_1[(cse_var_5 + 294912)])))
}
}
}
}
}
}
}
}
}
for (i1_2: int32, 0, 8) {
for (i2_2: int32, 0, 7) {
for (i3_2: int32, 0, 14) {
for (i5_2: int32, 0, 16) {
let cse_var_10: int32 = ((((i1_2*1568) + (i2_2*224)) + (i3_2*16)) + i5_2)
let cse_var_9: int32 = (cse_var_10 + 12544)
{
res_conv_2: Buffer(res_conv, int32, [157351936], [])[cse_var_10] = @tir.shift_right(res_conv_1[cse_var_10], 8, dtype=int32)
res_conv_2[cse_var_9] = @tir.shift_right(res_conv_1[cse_var_9], 8, dtype=int32)
}
}
}
}
}
for (i1_3: int32, 0, 8) {
for (i2_3: int32, 0, 7) {
for (i3_3: int32, 0, 14) {
for (i5_3: int32, 0, 16) {
let cse_var_12: int32 = ((((i1_3*1568) + (i2_3*224)) + (i3_3*16)) + i5_3)
let cse_var_11: int32 = (cse_var_12 + 12544)
{
res_conv_3: Buffer(res_conv, int32, [157351936], [])[cse_var_12] = max(res_conv_2[cse_var_12], 0)
res_conv_3[cse_var_11] = max(res_conv_2[cse_var_11], 0)
}
}
}
}
}
for (i1_4: int32, 0, 8) {
for (i2_4: int32, 0, 7) {
for (i3_4: int32, 0, 14) {
for (i5_4: int32, 0, 16) {
let cse_var_14: int32 = ((((i1_4*1568) + (i2_4*224)) + (i3_4*16)) + i5_4)
let cse_var_13: int32 = (cse_var_14 + 12544)
{
res_conv_4: Buffer(res_conv, int32, [157351936], [])[cse_var_14] = min(res_conv_3[cse_var_14], 127)
res_conv_4[cse_var_13] = min(res_conv_3[cse_var_13], 127)
}
}
}
}
}
for (i1.inner: int32, 0, 8) {
for (i2.inner: int32, 0, 7) {
for (i3.inner: int32, 0, 14) {
for (i5_5: int32, 0, 16) {
let cse_var_18: int32 = (i2.inner*224)
let cse_var_17: int32 = (i3.inner*16)
let cse_var_16: int32 = ((((i1.inner*1568) + cse_var_18) + cse_var_17) + i5_5)
let cse_var_15: int32 = (((((i1.inner*3136) + (i2.outer*1568)) + cse_var_18) + cse_var_17) + i5_5)
{
res[cse_var_15] = cast(int8, res_conv_4[cse_var_16])
res[(cse_var_15 + 25088)] = cast(int8, res_conv_4[(cse_var_16 + 12544)])
}
}
}
}
}
}
}
}
将拷贝降级到 DMA 传输
接下来,将缓冲区范围设置为相应的芯片 VTA SRAM 缓冲区。将加载循环移动到 2D 卷积计算循环中,暂存内存加载,使其适合芯片上 SRAM buffer。最后,用 DMA 拷贝编译指示来注释加载/存储循环外轴,从而在 VTA 上执行大容量内存传输。
# 设置 SRAM buffer 的范围
s[data_buf].set_scope(env.inp_scope)
s[kernel_buf].set_scope(env.wgt_scope)
s[res_conv].set_scope(env.acc_scope)
s[res_shr].set_scope(env.acc_scope)
s[res_min].set_scope(env.acc_scope)
s[res_max].set_scope(env.acc_scope)
# 块数据和内核缓存读取
s[data_buf].compute_at(s[res_conv], ic_out)
s[kernel_buf].compute_at(s[res_conv], ic_out)
# 用 DMA 拷贝编译指示操作 DRAM->SRAM
s[data_buf].pragma(s[data_buf].op.axis[0], env.dma_copy)
s[kernel_buf].pragma(s[kernel_buf].op.axis[0], env.dma_copy)
# 在每个结果块中的 SRAM->DRAM 操作上,使用 DMA 拷贝编译指示(这意味着这些拷贝应沿 b_inn 或结果轴 4 执行)
s[res].pragma(s[res].op.axis[4], env.dma_copy)
将计算降级为 VTA 计算内联函数
最后一个阶段是降级计算循环到 VTA 硬件内联函数,这是通过将 2D 卷积映射到张量内联函数,并将移位和裁剪计算映射到向量 ALU 实现的。
# 在 batch 张量平铺轴上应用张量化
s[res_conv].tensorize(b_tns, env.gemm)
# 在移位和裁剪操作上添加 ALU 编译指示
s[res_shr].pragma(s[res_shr].op.axis[0], env.alu)
s[res_min].pragma(s[res_min].op.axis[0], env.alu)
s[res_max].pragma(s[res_max].op.axis[0], env.alu)
# 将内存负载/存储降级为 DMA 拷贝内联函数,并将计算降级为 VTA 计算内联函数后,查看最终降级的 TVM schedule。
print(vta.lower(s, [data, kernel, res], simple_mode=True))
输出结果:
@main = primfn(data_1: handle, kernel_1: handle, res_1: handle) -> ()
attr = {"from_legacy_te_schedule": True, "global_symbol": "main", "tir.noalias": True}
buffers = {data: Buffer(data_2: Pointer(int8), int8, [50176], []),
kernel: Buffer(kernel_2: Pointer(int8), int8, [589824], []),
res: Buffer(res_2: Pointer(int8), int8, [50176], [])}
buffer_map = {data_1: data, kernel_1: kernel, res_1: res}
preflattened_buffer_map = {data_1: data_3: Buffer(data_2, int8, [1, 16, 14, 14, 1, 16], []), kernel_1: kernel_3: Buffer(kernel_2, int8, [16, 16, 3, 3, 16, 16], []), res_1: res_3: Buffer(res_2, int8, [1, 16, 14, 14, 1, 16], [])} {
@tir.vta.coproc_dep_push(3, 2, dtype=int32)
@tir.vta.coproc_dep_push(3, 2, dtype=int32)
for (i2.outer: int32, 0, 2) {
for (cthread.s: int32, 0, 2) {
attr [IterVar(vta: int32, (nullptr), "ThreadIndex", "vta")] "coproc_scope" = 2 {
@tir.vta.coproc_dep_pop(3, 2, dtype=int32)
attr [IterVar(vta, (nullptr), "ThreadIndex", "vta")] "coproc_uop_scope" = "VTAPushGEMMOp" {
@tir.call_extern("VTAUopLoopBegin", 8, 98, 0, 0, dtype=int32)
@tir.call_extern("VTAUopLoopBegin", 7, 14, 0, 0, dtype=int32)
for (j.init: int32, 0, 14) {
@tir.vta.uop_push(0, 1, ((cthread.s*784) + j.init), 0, 0, 0, 0, 0, dtype=int32)
}
@tir.call_extern("VTAUopLoopEnd", dtype=int32)
@tir.call_extern("VTAUopLoopEnd", dtype=int32)
}
@tir.vta.coproc_dep_push(2, 1, dtype=int32)
}
}
for (ic.outer: int32, 0, 16) {
let cse_var_6: int32 = (i2.outer*7)
let cse_var_5: int32 = (ic.outer*9)
let cse_var_4: int32 = max((1 - cse_var_6), 0)
let cse_var_3: int32 = max((cse_var_6 - 6), 0)
let cse_var_2: int32 = ((9 - cse_var_4) - cse_var_3)
let cse_var_1: int32 = ((((ic.outer*196) + (i2.outer*98)) + (cse_var_4*14)) - 14)
{
attr [IterVar(vta, (nullptr), "ThreadIndex", "vta")] "coproc_scope" = 1 {
@tir.vta.coproc_dep_pop(2, 1, dtype=int32)
@tir.call_extern("VTALoadBuffer2D", @tir.tvm_thread_context(@tir.vta.command_handle(, dtype=handle), dtype=handle), data_2, cse_var_1, 14, cse_var_2, 14, 1, cse_var_4, 1, cse_var_3, 0, 2, dtype=int32)
@tir.call_extern("VTALoadBuffer2D", @tir.tvm_thread_context(@tir.vta.command_handle(, dtype=handle), dtype=handle), kernel_2, cse_var_5, 9, 8, 144, 0, 0, 0, 0, 0, 1, dtype=int32)
@tir.vta.coproc_dep_push(1, 2, dtype=int32)
}
attr [IterVar(vta, (nullptr), "ThreadIndex", "vta")] "coproc_scope" = 1 {
@tir.vta.coproc_dep_pop(2, 1, dtype=int32)
@tir.call_extern("VTALoadBuffer2D", @tir.tvm_thread_context(@tir.vta.command_handle(, dtype=handle), dtype=handle), data_2, cse_var_1, 14, cse_var_2, 14, 1, cse_var_4, 1, cse_var_3, 144, 2, dtype=int32)
@tir.call_extern("VTALoadBuffer2D", @tir.tvm_thread_context(@tir.vta.command_handle(, dtype=handle), dtype=handle), kernel_2, (cse_var_5 + 1152), 9, 8, 144, 0, 0, 0, 0, 72, 1, dtype=int32)
@tir.vta.coproc_dep_push(1, 2, dtype=int32)
}
for (cthread.s_1: int32, 0, 2) {
attr [IterVar(vta, (nullptr), "ThreadIndex", "vta")] "coproc_scope" = 2 {
@tir.vta.coproc_dep_pop(1, 2, dtype=int32)
attr [IterVar(vta, (nullptr), "ThreadIndex", "vta")] "coproc_uop_scope" = "VTAPushGEMMOp" {
@tir.call_extern("VTAUopLoopBegin", 8, 98, 0, 9, dtype=int32)
@tir.call_extern("VTAUopLoopBegin", 7, 14, 16, 0, dtype=int32)
for (dy: int32, 0, 3) {
for (dx: int32, 0, 3) {
for (j: int32, 0, 14) {
@tir.vta.uop_push(0, 0, ((cthread.s_1*784) + j), ((((cthread.s_1*144) + (dy*16)) + j) + dx), (((cthread.s_1*72) + (dy*3)) + dx), 0, 0, 0, dtype=int32)
}
}
}
@tir.call_extern("VTAUopLoopEnd", dtype=int32)
@tir.call_extern("VTAUopLoopEnd", dtype=int32)
}
@tir.vta.coproc_dep_push(2, 1, dtype=int32)
}
}
}
}
@tir.vta.coproc_dep_pop(2, 1, dtype=int32)
@tir.vta.coproc_dep_pop(2, 1, dtype=int32)
for (cthread.s_2: int32, 0, 2) {
let cse_var_7: int32 = (cthread.s_2*784)
attr [IterVar(vta, (nullptr), "ThreadIndex", "vta")] "coproc_scope" = 2 {
attr [IterVar(vta, (nullptr), "ThreadIndex", "vta")] "coproc_uop_scope" = "VTAPushALUOp" {
@tir.call_extern("VTAUopLoopBegin", 784, 1, 1, 0, dtype=int32)
@tir.vta.uop_push(1, 0, cse_var_7, cse_var_7, 0, 3, 1, 8, dtype=int32)
@tir.call_extern("VTAUopLoopEnd", dtype=int32)
}
attr [IterVar(vta, (nullptr), "ThreadIndex", "vta")] "coproc_uop_scope" = "VTAPushALUOp" {
@tir.call_extern("VTAUopLoopBegin", 784, 1, 1, 0, dtype=int32)
@tir.vta.uop_push(1, 0, cse_var_7, cse_var_7, 0, 1, 1, 0, dtype=int32)
@tir.call_extern("VTAUopLoopEnd", dtype=int32)
}
attr [IterVar(vta, (nullptr), "ThreadIndex", "vta")] "coproc_uop_scope" = "VTAPushALUOp" {
@tir.call_extern("VTAUopLoopBegin", 784, 1, 1, 0, dtype=int32)
@tir.vta.uop_push(1, 0, cse_var_7, cse_var_7, 0, 0, 1, 127, dtype=int32)
@tir.call_extern("VTAUopLoopEnd", dtype=int32)
}
@tir.vta.coproc_dep_push(2, 3, dtype=int32)
}
}
for (cthread.s_3: int32, 0, 2) {
attr [IterVar(vta, (nullptr), "ThreadIndex", "vta")] "coproc_scope" = 3 {
@tir.vta.coproc_dep_pop(2, 3, dtype=int32)
for (i1.inner: int32, 0, 8) {
for (i2.inner: int32, 0, 7) {
for (i3.inner: int32, 0, 14) {
let cse_var_8: int32 = (i2.inner*14)
@tir.call_extern("VTAStoreBuffer2D", @tir.tvm_thread_context(@tir.vta.command_handle(, dtype=handle), dtype=handle), ((((cthread.s_3*784) + (i1.inner*98)) + cse_var_8) + i3.inner), 4, res_2, (((((cthread.s_3*1568) + (i1.inner*196)) + (i2.outer*98)) + cse_var_8) + i3.inner), 1, 1, 1, dtype=int32)
}
}
}
@tir.vta.coproc_dep_push(3, 2, dtype=int32)
}
}
}
@tir.vta.coproc_dep_pop(3, 2, dtype=int32)
@tir.vta.coproc_dep_pop(3, 2, dtype=int32)
@tir.vta.coproc_sync(, dtype=int32)
}
TVM 编译及验证
指定 schedule 后,可以将其编译为 TVM 函数。保存模块,以便通过 RPC 发送。运行这个函数,并根据 numpy 实现对其进行验证,以确保正确性。
# 用这个库进行 2D 卷积测试
from tvm.topi.testing import conv2d_nchw_python
# 编译 TVM 模块
with vta.build_config(disabled_pass={"tir.CommonSubexprElimTIR"}):
my_conv = vta.build(
s, [data, kernel, res], tvm.target.Target("ext_dev", host=env.target_host), name="my_conv"
)
temp = utils.tempdir()
my_conv.save(temp.relpath("conv2d.o"))
remote.upload(temp.relpath("conv2d.o"))
f = remote.load_module("conv2d.o")
# 获取远程设备上下文
ctx = remote.ext_dev(0)
# 在 NCHW 布局的 (-128, 128] int 范围内随机初始化数据和内核数组
data_np = np.random.randint(-128, 128, size=(batch_size, in_channels, height, width)).astype(
data.dtype
)
kernel_np = np.random.randint(
-128, 128, size=(out_channels, in_channels, kernel_h, kernel_w)
).astype(kernel.dtype)
# 将数据和内核数组从 2D NCHW 打包为 4D NCHWnc 打包布局
data_packed = data_np.reshape(
batch_size // env.BATCH, env.BATCH, in_channels // env.BLOCK_IN, env.BLOCK_IN, height, width
).transpose((0, 2, 4, 5, 1, 3))
kernel_packed = kernel_np.reshape(
out_channels // env.BLOCK_OUT,
env.BLOCK_OUT,
in_channels // env.BLOCK_IN,
env.BLOCK_IN,
kernel_h,
kernel_w,
).transpose((0, 2, 4, 5, 1, 3))
# 用 tvm.nd.array 将输入/输出数组格式化为 DLPack 标准
data_nd = tvm.nd.array(data_packed, ctx)
kernel_nd = tvm.nd.array(kernel_packed, ctx)
res_nd = tvm.nd.array(np.zeros(output_shape).astype(res.dtype), ctx)
# 清除统计
if env.TARGET in ["sim", "tsim"]:
simulator.clear_stats()
# 调用模块进行计算
f(data_nd, kernel_nd, res_nd)
# 针对 numpy 实现进行验证
res_ref = conv2d_nchw_python(
data_np.astype(env.acc_dtype),
kernel_np.astype(env.acc_dtype),
(stride_h, stride_w),
(pad_h, pad_w),
).astype(env.acc_dtype)
res_ref = res_ref >> env.INP_WIDTH
res_ref = np.clip(res_ref, 0, inp_max)
res_ref = res_ref.astype(res.dtype)
res_ref = res_ref.reshape(
(
batch_size // env.BATCH,
env.BATCH,
out_channels // env.BLOCK_OUT,
env.BLOCK_OUT,
fout_height,
fout_width,
)
).transpose((0, 2, 4, 5, 1, 3))
tvm.testing.assert_allclose(res_ref, res_nd.numpy())
# 打印统计
if env.TARGET in ["sim", "tsim"]:
sim_stats = simulator.stats()
print("Execution statistics:")
for k, v in sim_stats.items():
print("\t{:<16}: {:>16}".format(k, v))
print("Successful 2D convolution test!")
输出结果:
/workspace/python/tvm/driver/build_module.py:267: UserWarning: target_host parameter is going to be deprecated. Please pass in tvm.target.Target(target, host=target_host) instead.
"target_host parameter is going to be deprecated. "
Execution statistics:
inp_load_nbytes : 114688
wgt_load_nbytes : 1179648
acc_load_nbytes : 0
uop_load_nbytes : 1144
out_store_nbytes: 50176
gemm_counter : 451584
alu_counter : 9408
Successful 2D convolution test!
总结
本教程演示如何用 TVM 调度原语将 2D 卷积降级到硬件加速器内联函数上,利用硬件特定的优化,例如使用虚拟线程延迟隐藏。