TensorIR 快速入门
单击 此处 下载完整的示例代码
作者:Siyuan Feng
TensorIR 是深度学习领域的特定语言,主要有两个作用:
- 在各种硬件后端转换和优化程序。
- 自动 _tensorized_ 程序优化的抽象。
import tvm
from tvm.ir.module import IRModule
from tvm.script import tir as T
import numpy as np
IRModule
IRModule 是 TVM 的核心数据结构,它包含深度学习程序,并且是 IR 转换和模型构建的基础。
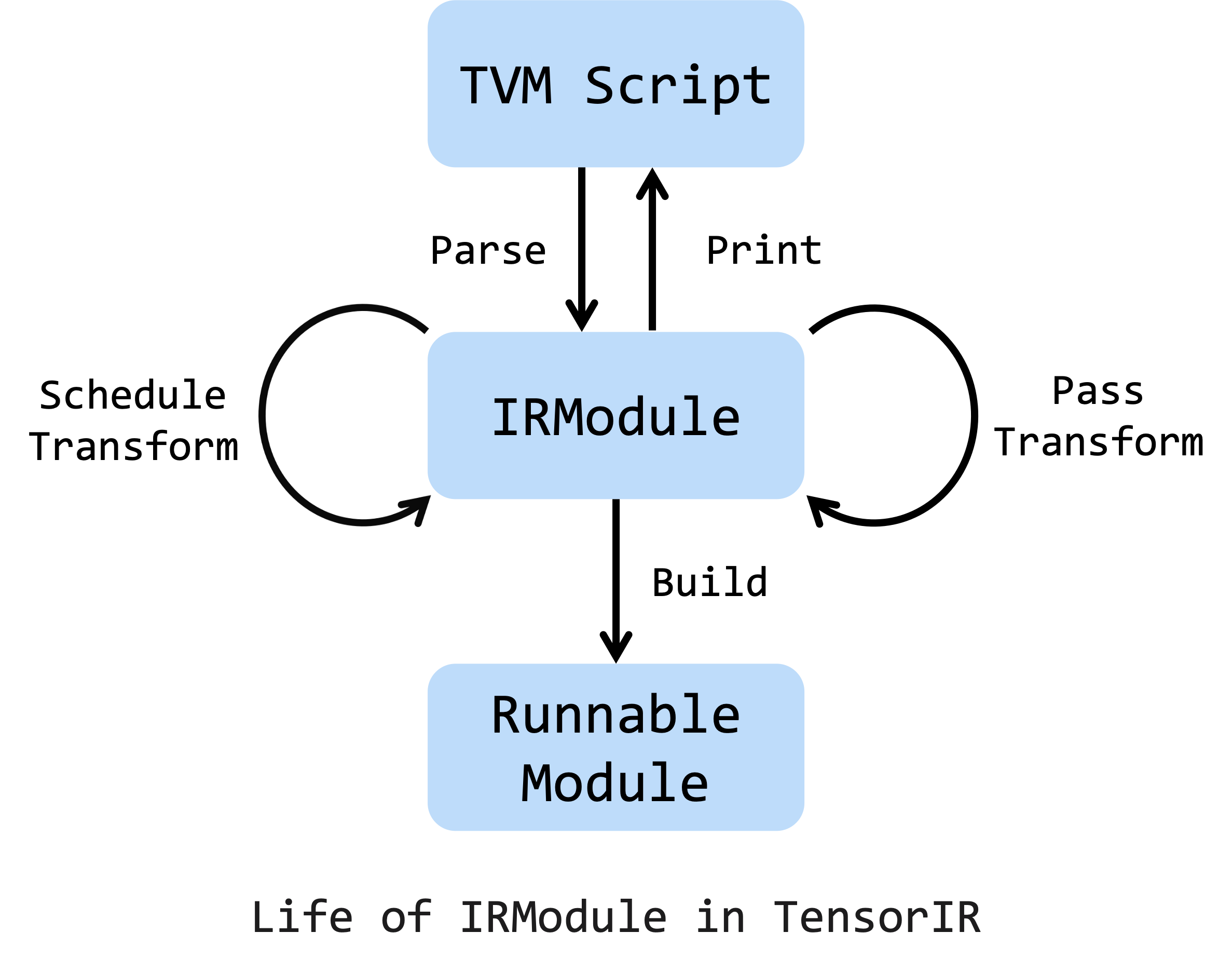
上图展示的是 IRModule 的生命周期,它可由 TVMScript 创建。转换 IRModule 的两种主要方法是 TensorIR 的 schedule 原语转换和 pass 转换。此外,也可直接对 IRModule 进行一系列转换。注意,可以在任何阶段将 IRModule 打印到 TVMScript。完成所有转换和优化后,可将 IRModule 构建为可运行模块,从而部署在目标设备上。
基于 TensorIR 和 IRModule 的设计,可创建一种新的编程方法:
- 基于 Python-AST 语法,用 TVMScript 编写程序。
- 使用 Python API 转换和优化程序。
- 使用命令式转换 API 交互检查和提高性能。
创建 IRModule
IRModule 是 TVM IR 的一种可往返语法,可通过编写 TVMScript 来创建。
与通过张量表达式创建计算表达式(使用张量表达式操作算子)不同,TensorIR 允许用户通过 TVMScript(一种嵌在 Python AST 中的语言)进行编程。新方法可以编写复杂的程序并进一步调度和优化。
下面是向量加法的示例:
@tvm.script.ir_module
class MyModule:
@T.prim_func
def main(a: T.handle, b: T.handle):
# 我们通过 T.handle 进行数据交换,类似于内存指针
T.func_attr({"global_symbol": "main", "tir.noalias": True})
# 通过 handle 创建 Buffer
A = T.match_buffer(a, (8,), dtype="float32")
B = T.match_buffer(b, (8,), dtype="float32")
for i in range(8):
# block 是针对计算的抽象
with T.block("B"):
# 定义一个空间(可并行)block 迭代器,并且将它的值绑定成 i
vi = T.axis.spatial(8, i)
B[vi] = A[vi] + 1.0
ir_module = MyModule
print(type(ir_module))
print(ir_module.script())
输出结果:
<class 'tvm.ir.module.IRModule'>
# from tvm.script import tir as T
@tvm.script.ir_module
class Module:
@T.prim_func
def main(A: T.Buffer[8, "float32"], B: T.Buffer[8, "float32"]) -> None:
# function attr dict
T.func_attr({"global_symbol": "main", "tir.noalias": True})
# body
# with T.block("root")
for i in T.serial(8):
with T.block("B"):
vi = T.axis.spatial(8, i)
T.reads(A[vi])
T.writes(B[vi])
B[vi] = A[vi] + T.float32(1)
此外,我们还可以使用张量表达式 DSL 编写简单的运算符,并将它们转换为 IRModule。
from tvm import te
A = te.placeholder((8,), dtype="float32", name="A")
B = te.compute((8,), lambda *i: A(*i) + 1.0, name="B")
func = te.create_prim_func([A, B])
ir_module_from_te = IRModule({"main": func})
print(ir_module_from_te.script())
输出结果:
# from tvm.script import tir as T
@tvm.script.ir_module
class Module:
@T.prim_func
def main(A: T.Buffer[8, "float32"], B: T.Buffer[8, "float32"]) -> None:
# function attr dict
T.func_attr({"global_symbol": "main", "tir.noalias": True})
# body
# with T.block("root")
for i0 in T.serial(8):
with T.block("B"):
i0_1 = T.axis.spatial(8, i0)
T.reads(A[i0_1])
T.writes(B[i0_1])
B[i0_1] = A[i0_1] + T.float32(1)
构建并运行 IRModule
可将 IRModule 构建为特定 target 后端的可运行模块。
mod = tvm.build(ir_module, target="llvm") # CPU 后端的模块
print(type(mod))
输出结果:
<class 'tvm.driver.build_module.OperatorModule'>
准备输入数组和输出数组,然后运行模块:
a = tvm.nd.array(np.arange(8).astype("float32"))
b = tvm.nd.array(np.zeros((8,)).astype("float32"))
mod(a, b)
print(a)
print(b)
输出结果:
[0. 1. 2. 3. 4. 5. 6. 7.]
[1. 2. 3. 4. 5. 6. 7. 8.]
转换 IRModule
IRModule 是程序优化的核心数据结构,可通过 Schedule 进行转换。schedule 包含多个 primitive 方法来交互地转换程序。每个 primitive 都以特定方式对程序进行转换,从而优化性能。
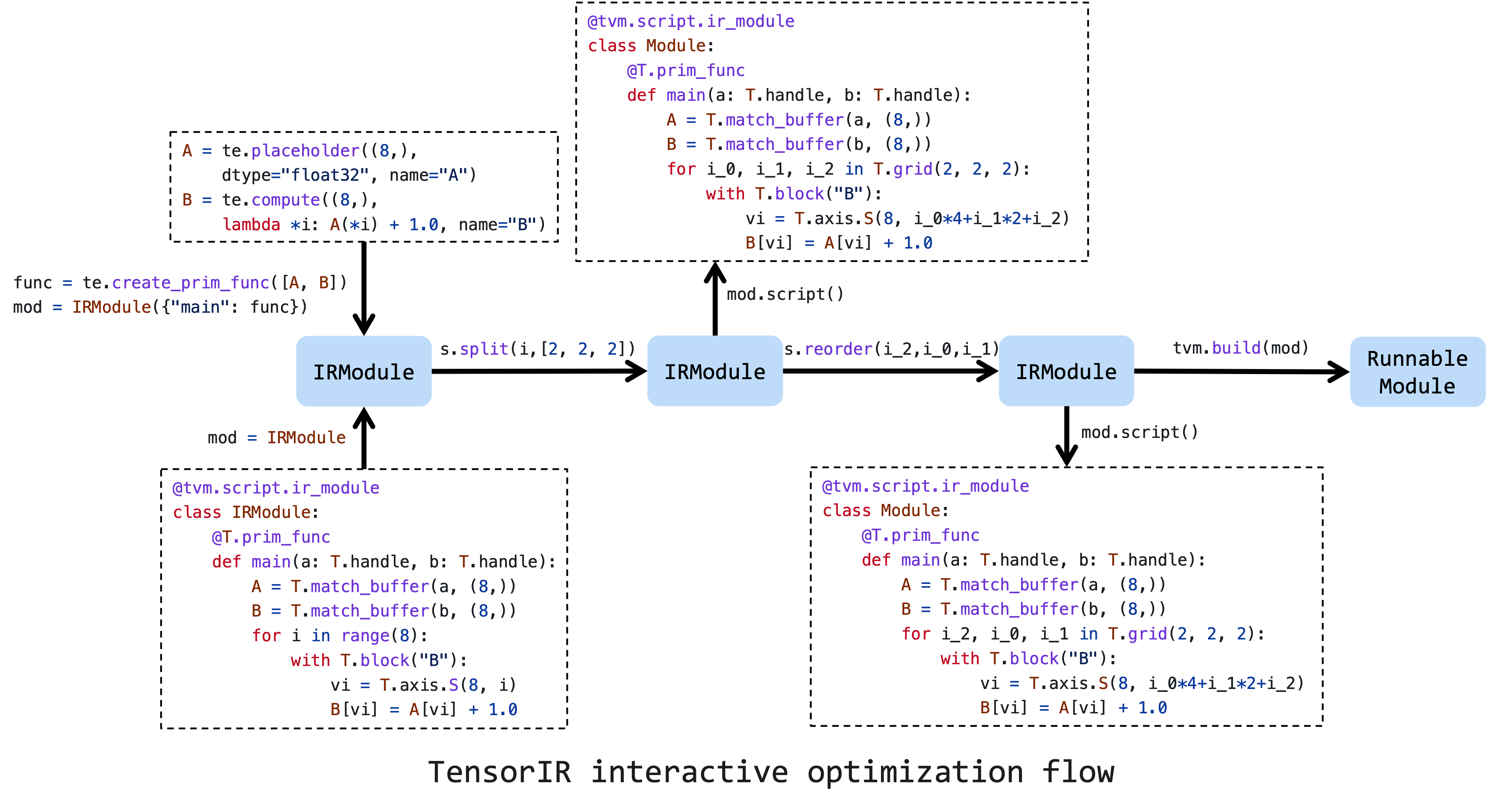
上图是优化张量程序的典型工作流程。首先,用 TVMScript 或张量表达式创建一个初始 IRModule,然后在这个初始 IRModule 上创建 schedule。接下来,使用一系列调度原语来提高性能。最后,我们可以将其降低并构建成一个可运行模块。
上面只演示了一个简单的转换。首先,在输入 ir_module 上创建 schedule:
sch = tvm.tir.Schedule(ir_module)
print(type(sch))
输出结果:
<class 'tvm.tir.schedule.schedule.Schedule'>
将嵌套循环展开成 3 个循环,并打印结果:
# 通过名字获取 block
block_b = sch.get_block("B")
# 获取包围 block 的循环
(i,) = sch.get_loops(block_b)
# 展开嵌套循环
i_0, i_1, i_2 = sch.split(i, factors=[2, 2, 2])
print(sch.mod.script())
输出结果:
# from tvm.script import tir as T
@tvm.script.ir_module
class Module:
@T.prim_func
def main(A: T.Buffer[8, "float32"], B: T.Buffer[8, "float32"]) -> None:
# function attr dict
T.func_attr({"global_symbol": "main", "tir.noalias": True})
# body
# with T.block("root")
for i_0, i_1, i_2 in T.grid(2, 2, 2):
with T.block("B"):
vi = T.axis.spatial(8, i_0 * 4 + i_1 * 2 + i_2)
T.reads(A[vi])
T.writes(B[vi])
B[vi] = A[vi] + T.float32(1)
还可对循环重新排序。例如,将循环 i_2 移到 i_1 之外:
sch.reorder(i_0, i_2, i_1)
print(sch.mod.script())
输出结果:
# from tvm.script import tir as T
@tvm.script.ir_module
class Module:
@T.prim_func
def main(A: T.Buffer[8, "float32"], B: T.Buffer[8, "float32"]) -> None:
# function attr dict
T.func_attr({"global_symbol": "main", "tir.noalias": True})
# body
# with T.block("root")
for i_0, i_2, i_1 in T.grid(2, 2, 2):
with T.block("B"):
vi = T.axis.spatial(8, i_0 * 4 + i_1 * 2 + i_2)
T.reads(A[vi])
T.writes(B[vi])
B[vi] = A[vi] + T.float32(1)
转换为 GPU 程序
要在 GPU 上部署模型必须进行线程绑定。幸运的是,也可以用原语来增量转换。
sch.bind(i_0, "blockIdx.x")
sch.bind(i_2, "threadIdx.x")
print(sch.mod.script())
输出结果:
# from tvm.script import tir as T
@tvm.script.ir_module
class Module:
@T.prim_func
def main(A: T.Buffer[8, "float32"], B: T.Buffer[8, "float32"]) -> None:
# function attr dict
T.func_attr({"global_symbol": "main", "tir.noalias": True})
# body
# with T.block("root")
for i_0 in T.thread_binding(2, thread="blockIdx.x"):
for i_2 in T.thread_binding(2, thread="threadIdx.x"):
for i_1 in T.serial(2):
with T.block("B"):
vi = T.axis.spatial(8, i_0 * 4 + i_1 * 2 + i_2)
T.reads(A[vi])
T.writes(B[vi])
B[vi] = A[vi] + T.float32(1)
绑定线程后,用 cuda 后端来构建 IRModule:
ctx = tvm.cuda(0)
cuda_mod = tvm.build(sch.mod, target="cuda")
cuda_a = tvm.nd.array(np.arange(8).astype("float32"), ctx)
cuda_b = tvm.nd.array(np.zeros((8,)).astype("float32"), ctx)
cuda_mod(cuda_a, cuda_b)
print(cuda_a)
print(cuda_b)
输出结果:
[0. 1. 2. 3. 4. 5. 6. 7.]
[1. 2. 3. 4. 5. 6. 7. 8.]